The contents of this page are meant to be memos for myself, but I will post it publicly here with the hope that someone else may find it useful, and more importantly, to motivate myself using peer pressure to learn more.
Transformer output is “conditioned” on the robot morphology
create 1D series of tokens (using depth-first traversal of kinematic tree) and embed each token with proprioceptive and morphological information (doesn’t it lose information about the whole tree if it’s just a depth first search?)
the morphology representation \(s^k_m\) is combined with proprioceptive states \(s^k_p\) into \(s_l^k \in R^{N \times M}\) (what are \(N\) and \(M\)?)
I don’t understand the embedding process at eq. (1)- where is it in the code?
can generalize zero-shot to new dynamics, kinematics, morphologies, tasks (!)
How transformers are used in RL?
Transformers are used as policy and critic networks
finetuning the model is 2~3 times faster than training from scratch (I hope it can be even faster…)
MAML: standard method for meta-learning
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep
networks,” Mar. 2017..
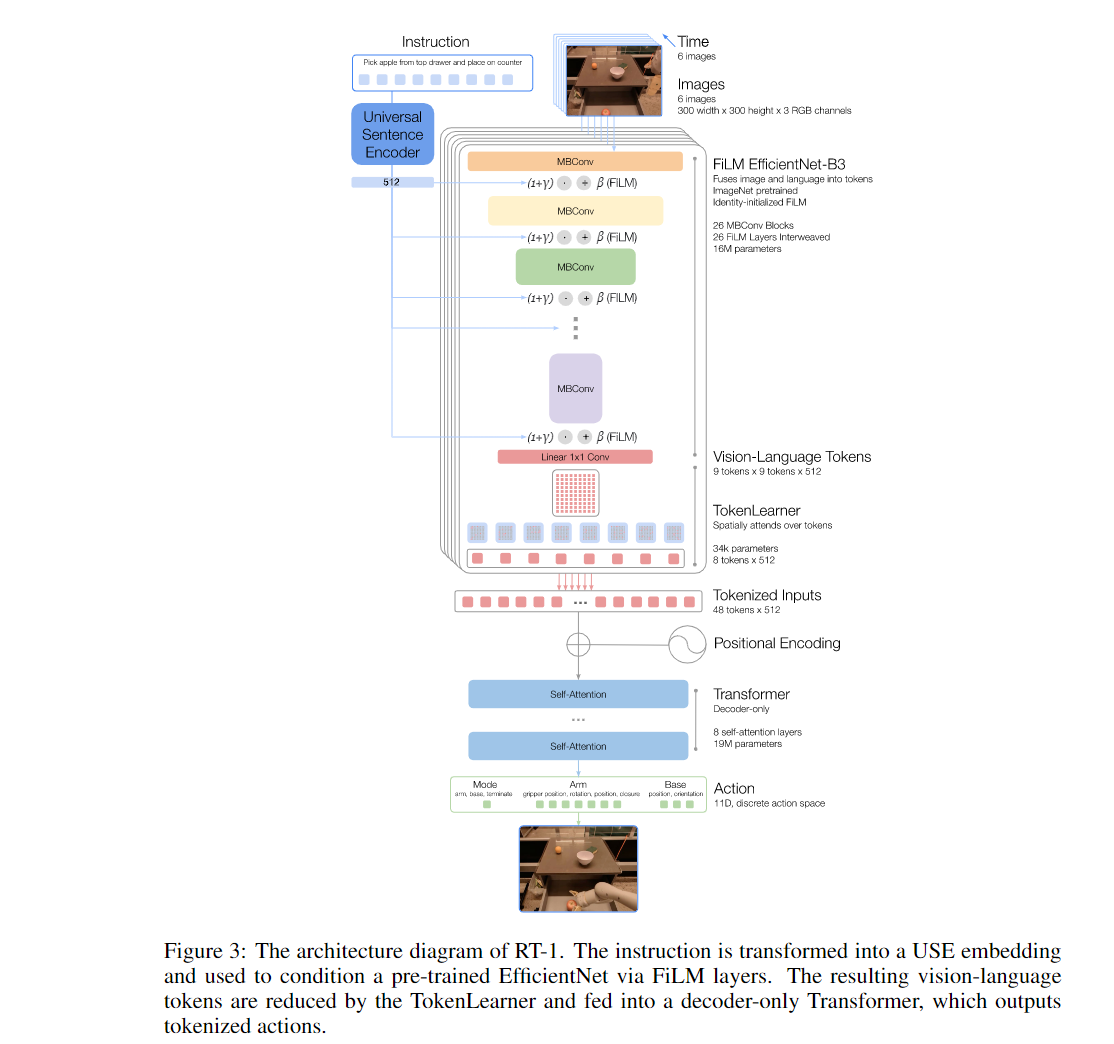
Transformer model (sequence mapping) for robot movements
GPT-3 but for robots?
dataset: gathered over 17 months with 13 robots, 130k episodes, 700 tasks
not RL- more like behavior cloning, replicating what has been previously demonstrated
技のデパート
image and text preprocessed with ImageNet pretrained CNN, conditioned (what does that mean) on pretrained embedding of the instruction (via “FiLM”)
Token Learner to compute comapct set of tokens
Transformer to produce discretized action tokens from those
actions: 7dof for arm, xyzrpy and gripper opening. 3 dof for base (xy yaw)
runs at 3 Hz
adding simulated demonstration to the dataset does not degrade performance for existing tasks, and improves performance of tasks only seen in simulation
ditto for adding data from another robot (with same type of action space)
significance
command robots with language like never before; like ChatGPT but with robots, it can receive natural language commands and execute
generalize to new tasks by adding new demonstrations (like DreamBooth)
can be used as basis for new task training (like a core part of the brain)
an uncanniliy good system to convert input into output, by solely uisng attention (of recurrent connections)
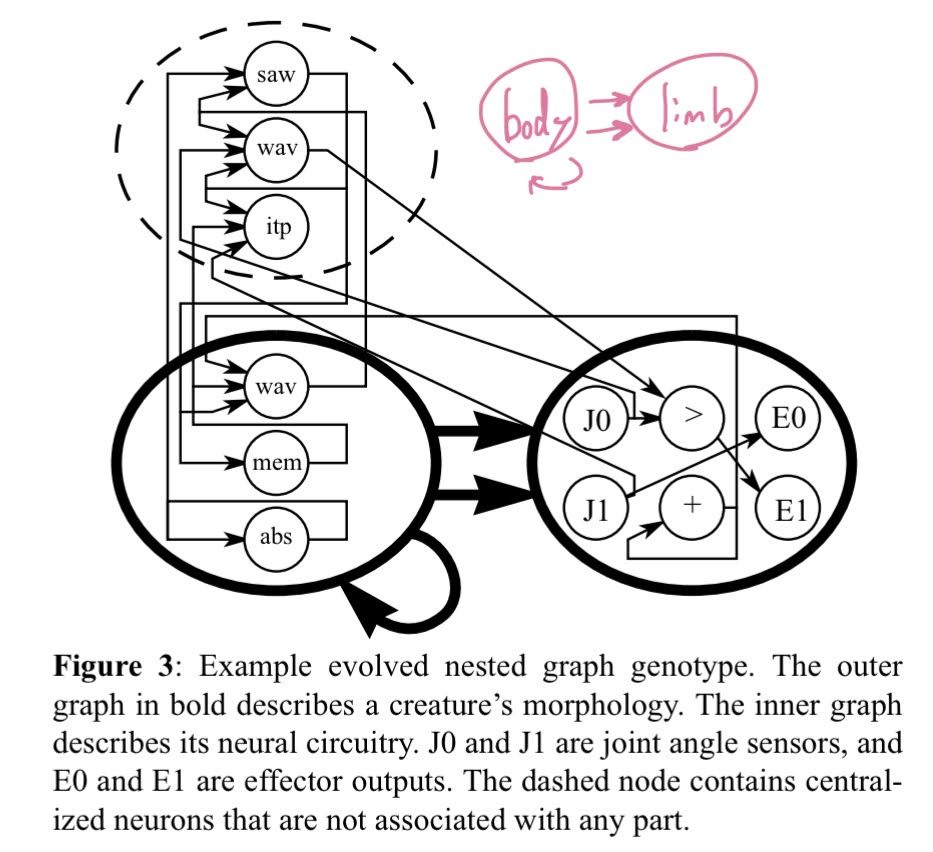
Karl Sims - Evolving Virtual Creatures
“OOPAart of RL and genetic algorithms”
K. Sims, “Evolving virtual creatures,” in Proceedings of the 21st annual conference on Computer graphics
and interactive techniques, in SIGGRAPH ’94. New York, NY, USA: Association for Computing Machinery, July 1994, pp. 15–22..
read: 22.11.2022
somehow this is from 1994
concepts of genotype and phenotype
genotype: genes, the directed graph representing the rule to generate the creature. could be a recursive rule (with a limit to how many recursions are allowed)
phenotype: the physical representation generated by compiling the rule defined in the genotype
controller (neural network) is created with the same concept- “In this way the genetic language for morphology and control is merged”
fitness value calculated for all creatures and only the most fittest survive
three types of modifications (4:3:3)
mutation: vary parameters, add new nodes or connections (garbage collect unconnected elements)
mate two graphs with crossover (like how genes mesh together, forgot how it was called…)
mate two graphs with graft, connect one node of parent to random node of another
how is controller initialised?
RoboGrammar
A. Zhao et al., “RoboGrammar,” ACM Trans. Graph., vol. 39, no. 6, pp. 1–16, Dec. 2020..
graph-based “grammar” (a set of rules) describing the robot body structure: e.g. enforce symmetry, joints connect links, feasible to build
heuristic function accepts that graph as argument and outputs the best possible design starting from that graph (Q-learning-like training method with epsilon-greedy search)
GNNs allow input of graphs
what it’s trying to do is very similar to Karl Sims
Karl Sims method could port the controller over during mutations since it was tied to the “genotype”, but here sampling-based MPC is used (MPPI, which uses sum of best control input weighted based on performance) (same as PDDM model-based dex manip)
interested how the graph is programatically implemented
I like Sims’ method more which can allow the controller to be mutated together with body, and not generated from scratch every time using MPC
adjust shape of link using cage-based deformation for expressive yet efficient shape optimization
differentiable sim; kind of like DiffPD, optimize shape and control input at the same time
movements are rather simple and “single-step” movements (roll cube, reach a point, etc)
joint structure optimization is not the focus; initial component blocks are given
diff’able but the joint link structure is discrete so can’t be diff’ed?
very simplistic sim2real shown (control input was determined manually, presumably because the optimized control input didn’t work irl)
was the kinematic structure optimized? -> they say it could be done (in V. Discussion) but haven’t done it. It would also not be differentiable…
Graph Neural Networks
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini, “The graph neural network model,” IEEE Trans. Neural Netw., vol. 20, no. 1, pp. 61–80, Jan. 2009..
Z. Cao, I. Radosavovic, A. Kanazawa, and J. Malik, “Reconstructing Hand-Object Interactions in the Wild,” Dec. 2020..
read: 11.2022
detect keypoints of hand -> fit to hand model
detect object mask (3D model of object is given), use differentiable rendering to fit to image.
interestingly, they also use estimated depth map from monocular 2D image and use that as the sensed information too (-> monocular depth estimation methods are that good?)
after separately reconstructing hand and object, jointly optimize them to “make sense”; hand touches object but doesn’t intersect it, etc, using various loss funcs
Completely model-based optimization of gripper structure
C. Hazard, N. Pollard, and S. Coros, “Automated design of manipulators for in-hand tasks,” in 2018 IEEE-RAS 18th International Conference on Humanoid
Robots (Humanoids), IEEE, Nov. 2018..
read: 24.11.2022
multi-step model-based optimization procedure
floating contact optimization: cost functions that make sure the object is moved towards the desired orientation. output is the floating contact point and forces.
Mechanism synthesis continuous optimization: optimize the continuous morphological parameters of the hand so that the contact points are achieved and there is no collision. Not sure what method is used for the optimization. (probably numerical optimization)
Mechanism synthesis discrete optimization: change the joint structure.
adds so many cost functions that works out together in the end
pipeline structure disallows later result “going back” to modify earlier outputs in the pipeline
the video is pretty cool- seems it can’t break and make contact? and some motions seem physically infeasible (looks like it’s slipping,)
Joint optimization of design and controller using DRL
C. Schaff, D. Yunis, A. Chakrabarti, and M. R. Walter, “Jointly Learning to Construct and Control Agents using Deep
Reinforcement Learning,” https://openreview.net › forumhttps://openreview.net › forum, 2018..
read: 29.11.2022
first to do joint optimization of design and control in a model-free manner (previous ones used model-based optimization / control somewhere)
use PPO for DRL
design is described as multi-modal distribution over the parameters (uni-modal Gaussian tended to get stuck frequently in local minima)
how is it updated when the gradients are not available?
same controller is controlled for all sampled designs (the network is given the design parameters sampled for that instance of the robot)
the discrete joint structure is not modified, only the continuous parameters
alternating optimization between design and control “yield convergence to better solutions in a resonable number of iterations compared to performing simultaneous updates”.
using a common controller lets it learn common strategies across diverse designs
they have a follow-up paper doing sim2real on a soft crawling robot
DRL-based manipulation in MuJoCo
A. Rajeswaran et al., “Learning Complex Dexterous Manipulation with Deep
Reinforcement Learning and Demonstrations,” Sept. 2017..
had error about missing GLIBCXX_3.4.29 when creating the conda environment as written in the README, so just installed mjrl and mj_envs locally (pip3 install -e .) which let me run the sample programs.
may have to change mujoco-py version in mj_envs/setup.py
quick points
by using human demonstrations, captured through a glove, DRL can learn more efficiently
(one of?) the first to apply model-free learning to anthropomorphic hands
IO
sensed data: hand joint angles, object and target pose
actions: desired hand joint angles
for in-hand manipulation, collecting human demo data is difficult, so used “computational expert trained using RL on a well shaped reward for many iterations”
small noise added to demo data, to combat distribution drift
want to get stochastic policy \(\pi_\theta: S \times A \rightarrow \mathbb R_+\)
The “Natural Policy Gradient” algorithm used to optimize the parameters \(\theta\) of the policy (the what???)
behavior cloning tries to maximize the likelihood for the policy to replicate the demonstrated behavior;
\(\Sigma_{(s, a) \in \rho_D} ln(\pi_\theta (a|s))\)
but the cloned policies alone are not successful in completing a task.
The following gradient augmented with the demo data is used, where \(w(s,a)\) is the weighting function to adjust how much effect demo data has (the “heuristic” weighting function is described in paper). DAPG: Demo Augmented Policy Gradient
\[g_{aug} = \Sigma_{(s, a) \in \rho_\pi} \nabla_\theta ln(\pi_\theta (a|s)) A^\pi(s, a) + \\
\Sigma_{(s, a) \in \rho_D} \nabla_\theta ln(\pi_\theta (a|s)) w(s,a)\]
what is the reward? sparse or shaped? -> DAPG works with sparse task completion reward
one of the resampling (here probably means to validate models by using random subsets) methods, which use random sampling w/ replacement. Bootstrapping estimates the properties of an estimator (e.g. its variance) by measuring it by sampling from an approximating distribution. (the height measurement example in Wikipedia is easy to understand)
temporal difference learning bootstraps from the current estimate of the value function.
TD(0) method is a special simple case of TD methods, estimating state value function (the expected return of starting from state \(s\) and following policy \(\pi\) ) of a finite state MDP.
The HJB equation, which is the N-S condition for optimal control
TD error is the difference bet. current estimate for \(V\) and the actual reward gained (plus discounted estimate of next state). But more effective to estimate the action-value pair?
with \(Q(x,a)\), actions can be made explicit so it could be used where there are no transition models. But could be problematic if there is a large action space.
if the transition function can be obtaind, \(V(s)\) could be used too.
SARSA
on-policy TD control method, where the estimate of \(q_\pi (s_t, a_t)\) is dependent on the current policy \(\pi\) and assumed that this policy will be used for all of rest of the agent’s episode. A problem is that it is sensitive to current policy that the agent is following.
on-policy: assumes the current policy is used by the agent for the whole learning process. SARSA is on-policy. “more stable, and scale well to high dimensional spaces”
off-policy: uses some other policy (like greedy search) during learning. Q-learning is off-policy. “more sample efficient when successful, but more unstable”
distribution drift?
DDPG: Deep Deterministic Policy Gradient (DDPG) & Normalized Advantage Function (NAF)
T. P. Lillicrap et al., “Continuous control with deep reinforcement learning,” Sept. 2015..
this has been proven to be the gradient of the policy’s performance, i.e. the policy gradient.
what is \(\rho^\beta\)? the replay buffer?
is computing the expected value for the gradient wrt the actor parameters of the current Q function, starting from \(s_t\) and following the actor function.
what is new with DDPG (wrt DPG
modifications inspired by DQN, allwing it to use NN to learn in large state and action spaces online (so… it has same concepts as DPG?)
add replay buffer like in DQN, which stores the tuple \((s_t, a_t, r_t, s_t+1)\). Seems like a fixed-size LIFO queue?
add “batch normalization”
from video…
uses off-policy critic \(Q_w\) which learns from replay buffer
for on-policy learning, singe objective: relentlessly improve policy
for off-policy, two objectives: improve the off-policy critic which looks at the replay buffer, and to maximize the value of the critic
DQN is suitable when action space is discrete / small (difficult to run the “max” step)
actor-critic structure
actor sends actions to environemnt
critic outputs a single scalar value indicating expected cumulative reward
DeepMind Lecture: Reinforcement Learning 6: Policy Gradients and Actor Critics
watched 20220429-20220510
Never solve a more general problem as an intermediate step - Vladimir Vapnik, 1998
-> why not learn a policy directly (rather than learning the Q value)
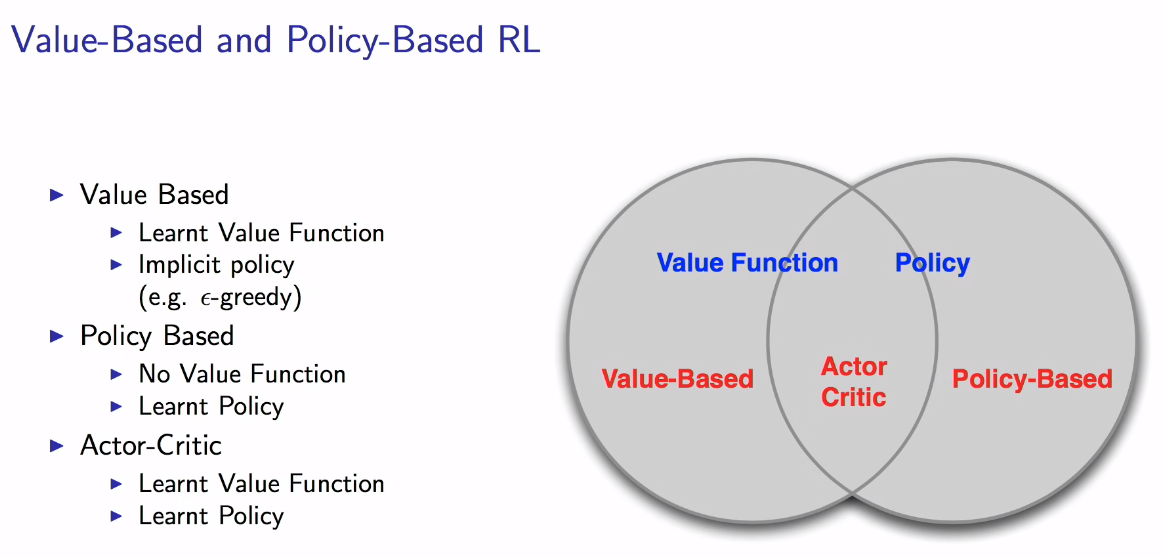
approximating parametric value functions vs parametric policy directly
sometimes policies are simple, while models and values are complex
policy-based is subject to local optima, and obtained knowledge is specific and does not generalize well
being able to learn stochastic policies is beneficial because…
policy could be easily guessed, think rock-paper-scissors
deterministic policies could get stuck (20:00)
compute the policy gradient, i.e. gradient of an objective function for the policy \(J(\theta)\)
use Monte Carlo sampling for the gradinet, but a problem is that the gradient of an expectation cannot be computed. So it is converted (the score function trick / log likelihood trick) to an expectation of the gradient value.
Policy gradient theorem: instanteneous reward (in the score function trick) can be replaced with long-term value (45:53)
“copies / variants” of \(\pi^m\) enable simultaneous training on multiple simulations
the “loss” is in quotes because it is intended to “trick” the DL program to compute the gradient, which then is the update rule that we want
A2C: advantage actor-critic
Trust region policy optimization
careful with updates: bad policy leads to bad data. On the other hand in supervised learning, learning and data are independent.
one solution is to regularize policy to not change too much, to prevent instability
limit difference between subsequent policy, e.g. by using KL divergence.
maximize \(J(\theta) - \nu KL(\pi_{old}|\pi_\theta)\)
for some small \(\nu\) (instead of just \(J(\theta)\))
Often used in practice: trust region policy optimization (TRPO) and proximal policy optimization (PPO) both try to find solutions that are close to the current solution, because that’s safer and more stable.
Gaussian policy is common in continuous action spaces.
gradient of the log of the policy is
\(\nabla log \pi_\theta(s,a) = \frac{a - \mu(s)}{\sigma^2} \nabla \mu(s)\) (if just the mean is parametrized and the variance is fixed)
something perhaps even simpler: Cacla (continuous actor-critic learning automaton)
![/assets/2022/cacla.png]
update the actor whenever the TD error is positive
Much more intuitive explanation of the same topic
<div class=“youtube-player” data-id=“zR11FLZ”></div>
S. Gu, T. Lillicrap, I. Sutskever, and S. Levine, “Continuous Deep Q-Learning with Model-based Acceleration,” Mar. 2016..
Model-based dexterous manipulation
V. Kumar, Y. Tassa, T. Erez, and E. Todorov, “Real-time behaviour synthesis for dynamic
hand-manipulation,” in 2014 IEEE International Conference on Robotics and
Automation (ICRA), IEEE, May 2014..
I. Mordatch, Z. Popović, and E. Todorov, “Contact-invariant optimization for hand manipulation,” in Proceedings of the ACM SIGGRAPH/Eurographics Symposium on
Computer Animation, in SCA ’12. Goslar, DEU: Eurographics Association, July 2012, pp. 137–144..
referenced as examples of model-based manipulation by Rajeswaran2017
Emo Todorov is involved in both of these (as with Rajeswaran2017)
MPC based on stochastic MDP modelled with DNN
A. Nagabandi, K. Konoglie, S. Levine, and V. Kumar, “Deep dynamics models for learning dexterous manipulation,” Sept. 2019..
not sure what state / action space is used… it’s not written in the paper as far as I saw… secret sauce?
being model-based is more sample efficient
PDDM (planning with deep dynamics models)
learn a deep dynamics model as stochastic MDP model (using a fixed covariance did not impact performance that much)
learn model parameters to maximize log likelihood of the observations
use “bootstrap ensembles” where \(i = 1, 2 \dots E\) models are prepared, which is a simple and inexpensive way to “capture epistemic uncertainty in network weights”.
start each model with different initial random weights, and use different batch of data \(D_i\) at each training step.
use short-horizon MPC (trajectory optimization) for control.
use gradient-free method (therefore a lot of sampling is required?)
Random Shooting and Iterative Random-Shooting with Refinement are simple enough (pure random, or random but refined based on best samples)
Model-free dexterous manipulation
H. van Hoof, T. Hermans, G. Neumann, and J. Peters, “Learning robot in-hand manipulation with tactile features,” in 2015 IEEE-RAS 15th International Conference on Humanoid
Robots (Humanoids), IEEE, Nov. 2015..
read 19.05.2022
first to apply RL to in-hand manipulation
state representation for each finger (6DoF):
tactile sensor
proximal joint angle
distal joint angle
action: velocity for 2 timesteps (2DoF, finger is underactuated)
reward function: weighted sum of [sumsq(action)], [pressing force is close to target], [object position is close to target]
math is way beyond what I can currently understand (“relative entropy policy search”)
roll a bottle-like object across the table: fairly simple task
learn in the real world
S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep Reinforcement Learning for Robotic Manipulation with
Asynchronous Off-Policy Updates,” Oct. 2016..
read 21.05.2022
referenced in Rajeswaran2017
the (probably famous) experiment by Google with multiple robots learning in parallel
but I also remember the one where the robot picks up multiple objects, whereas this one it’s just a door opening task (and no vision is used)
why did this method fall out of fashion? improvement of simulators? shift towards data-hungry methods that are just intractable for physical robots?
learn policy to open door, from scratch with no priors, in 2.5 hours with 2 robots
reward function is a bit “engineered” as it includes distance bet. hand and handle, distance bet. ideal door handle & hinge angle (doing this with sparse rewards only when it succeeds, is much more difficult)
the learning curve reflects this, as there is a plateau when robot can reach the handle (but not open door)
state and action representation varies slightly in each task but for the door task…
joint angle, end-effector position and their time derivatives
door angle and hingle angle
door frame position
actions are joint velocities
DDPG and NAF (normalized advantage function) were compared in sim but only latter used for real robot
NAF “restricts the class of Q-function to the expression below to enable closed-form updates, as in the discrete action case”
O. Khatib, “Real-Time Obstacle Avoidance for Manipulators and Mobile
Robots,” Int. J. Rob. Res., vol. 5, no. 1, pp. 90–98, Mar. 1986..
read: 10.04.2022
somehow there are two versions of this paper, in 1985 and 1986
basically a common sense by now, to use potential fields for obstacle avoidance
much of paper is about manipulators rather than mobile robot navigation, even though the latter feels like a more obvious application to this method
possibly replace planning methods like A*
acknowledges that local minima is an issue
describes potential field functions for various primitives
Define potential energy towards goal and against obstacles (FIRAS, “Force Inducing an Artificial Repulsion from the Surface”, but in the French word order?)
where \(\rho\) is the shortest distance to the obstacle, and the \(\rho_0\) is the limit of influence of the potential field.
RL-based walking with ANYmal
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V. Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in
the wild,” Science Robotics, vol. 7, no. 62, p. eabk2822, 2022.
H. Wang, B. Yang, Y. Liu, W. Chen, X. Liang, and R. Pfeifer, “Visual Servoing of Soft Robot Manipulator in Constrained
Environments With an Adaptive Controller,” IEEE/ASME Trans. Mechatron., vol. 22, no. 1, pp. 41–50, Feb. 2017..
collect the camera intrinsic and extrinsic parameters and the base frame of the robot into the matrix \(A \in \mathbb R^{2 \times 6}\) and vector \(b\), as
\[\dot y = \frac{1}{z(q)} A(y, q) \begin{bmatrix} v \\ w \end{bmatrix} \\
\dot z = b(q) \begin{bmatrix} v \\ w \end{bmatrix}\]
where \(y\) is image coords, \(v\) and \(w\) are end effector velocity (pos & rot).
\(A\) and \(b\) are somehow parametrized by the vector \(a\) (not really clear how?), and an adaptive law is defined, and the convergence is proven through Lyapunov analysis
camera is at robot tip, and tries to control the position of a feature point in the image (a dot)
seems like a pretty straightfoward application of adaptive control + visual servoing to soft robots. wish there was a video…
Apple Machine Learning Reserach
read: 20.04.2022
not an academic paper but interesting look into how Apple implements ML into their products.
to make the NN compact enough to run on a mobile device, “teacher-student” training method was used (cites this paper).
This approach provided us a mechanism to train a second thin-and-deep network (the “student”), in such a way that it matched very closely the outputs of the big complex network (the “teacher”) that we had trained as described previously.
Panoptic segmentation unifies scene-level and subject-level understanding by predicting two attributes for each pixel: a categorical label and a subject label.
distinguish between sky, person, hair, skin, teeth, and glasses
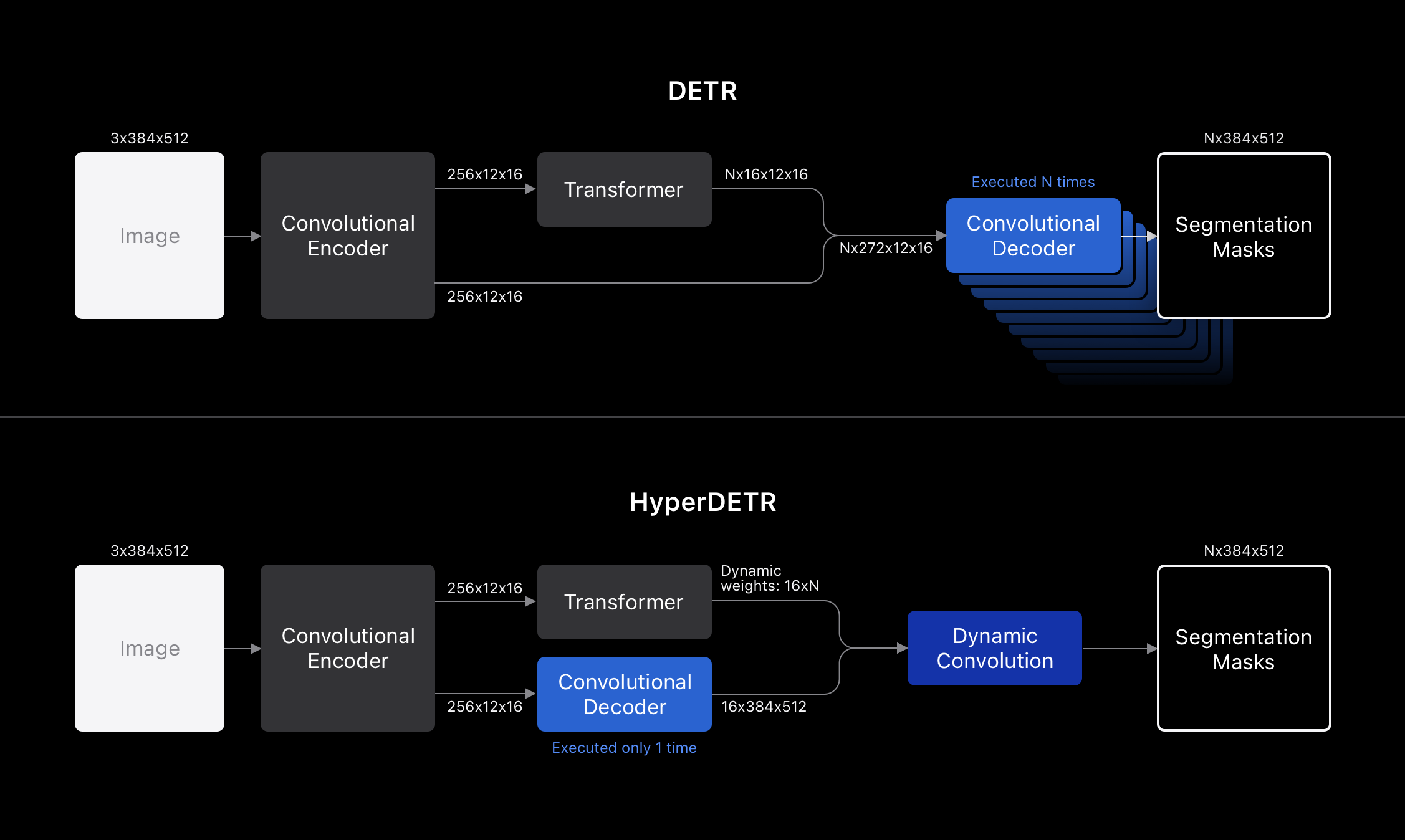
“Detection Transformer” (DETR) architecture used as baseline (but not efficient when extending to panoptic segmentation)- thus, “HyperDETR” is proposed, which integrates panoptic segmentation into the architecture.
Panoptic segmentation
A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár, “Panoptic Segmentation,” Jan. 2018.
tbh so much simpler than I imagined- the learning process is exactly the same as the standard tutorial for ML, and the very same network (U-Net in this case) could also possibly be used for classification (as long as the output dimensions are correct). It’s the network structure that makes it better suited for segmentation, but in theory, segmentation could also be done with a conventional MLP. It sounds like dataset collection & annotation is the hard part…
Foundation Models
R. Bommasani et al., “On the Opportunities and Risks of Foundation Models,” Aug. 2021..
read: 20220422
this is a super long (>200p) review so I mostly only read the first part and the robotics part
BERT, DALL-E, GPT-3 are all examples of foundational models
transformer architecture
demonstrate the importance of capturinglong-range dependenciesandpairwise or higher-order interactions between elements.
in robotics, “task specification” and “task learning” are important opportunities for foundational models
how to specify goal with clarity so that robots can “understand”- convert into a “reward function”
how robots can achieve that goal
not sure what type of data is needed
different problems have different input-output data
Soft Robotics for Delicate and Dexterous Manipulation (ICRA2021 talk)
Prof. Robert J. Wood’s talk at ICRA
an application where soft grippers make a lot of sense; exploration of marine life
apply soft material to not just simple gripping, but dexterous manipulation as well
add more DoFs in a serial vs parallel manner
computational design with “SoMo” (based on PyBullet) to find most effective config (31:00)
use “palm” to assist manipulation (IHM = in-hand manipulation) (33:39)
tune friction of fingertip using bubble-wrap like material
C. B. Teeple, B. Aktas, M. C. Yuen, G. R. Kim, R. D. Howe, and R. J. Wood, “Controlling Palm-Object Interactions Via Friction for Enhanced
In-Hand Manipulation Controlling Palm-Object Interactions
Via Friction for Enhanced In-Hand Manipulation,” IEEE Robotics and Automation Letters, vol. 7, pp. 2258–2265..
I feel this would be a good paper to see how to approach research of soft gripper-based manipulation
M. A. Graule, T. P. McCarthy, C. B. Teeple, J. Werfel, and R. J. Wood, “SoMoGym: A toolkit for developing and evaluating controllers
and reinforcement learning algorithms for soft robots,” IEEE Robot. Autom. Lett., vol. 7, no. 2, pp. 4071–4078, Apr. 2022..