

数日前、ChatGPTでちょっとした実験をしてみました。「パーソナライズ」設定で「ウェブ検索」機能をオフにした状態で色々聞いてみたのです。そうしたら、予想外の答えが返ってきました:
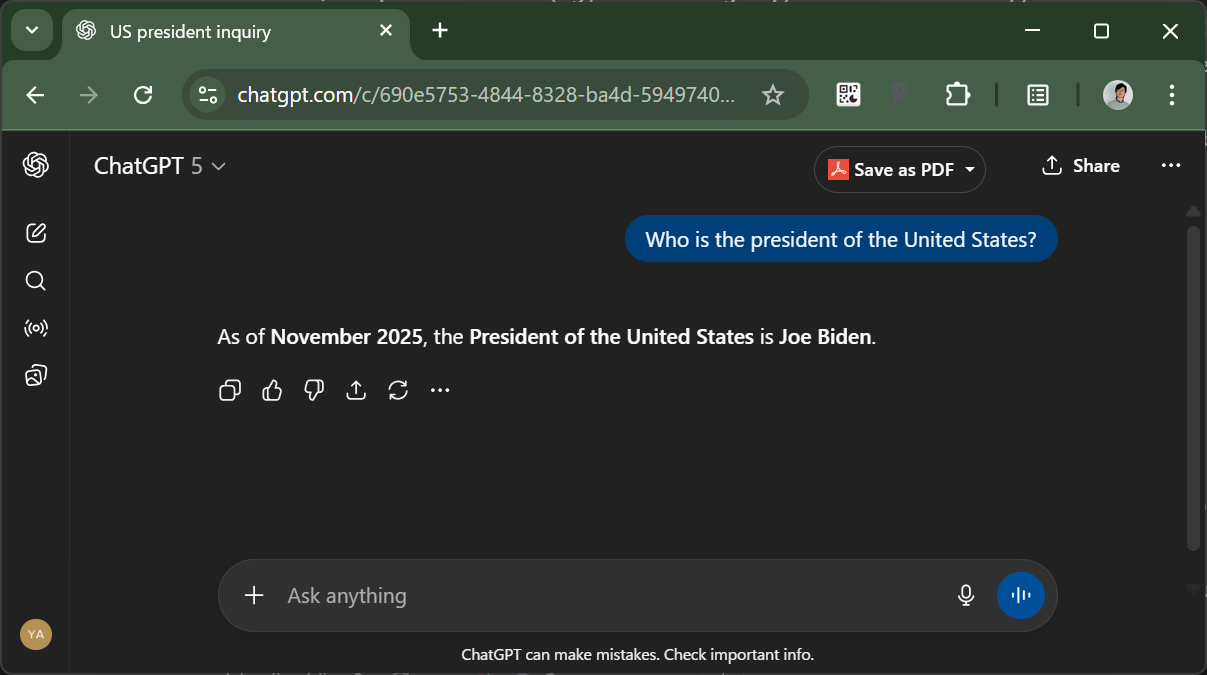
GPT-5の学習用の文章は2024年6月までのものしか含まれていないので、2024年11月のアメリカ大統領選の結果は知らないはずです。だから未だにバイデン大統領と答えても不思議ではない!…と考えるのは早計です。2024年末に大統領選があることは一般常識な上、ChatGPTは現在の日付を知っています(OpenAIが用意したシステムプロンプトに含まれている)。なので、ここでは「現在の大統領は分からない」と答えるのが正解なはずなのです。
「考える」モードではもうちょっとマシでした。12秒間「思考」した後、ウェブ検索機能が使えないため最新情報は分からない、と答えてくれます。
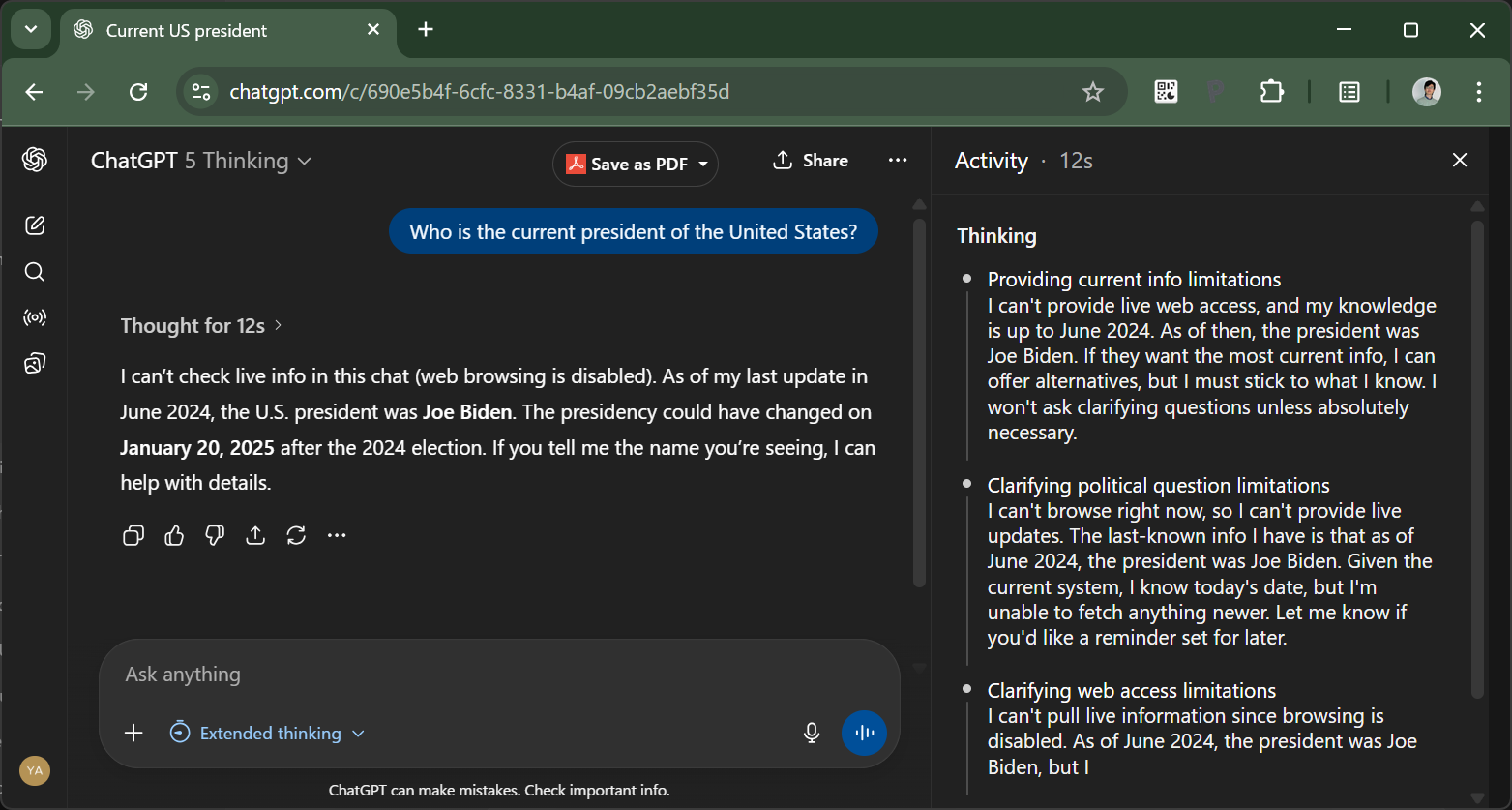
しかしながら、数百億円かけて学習(研究開発も含めると数千億レベル?)したといわれるGPT-5のベースモデルがこの有様でいいのでしょうか。 他にどんな簡単な質問で躓くのか、色々試したくなってちょっとしたテストをしてみました。
Pt.1:「ちょっとしたテスト」にしてはやたらと凝ったシステムを構築
大量のサンプルを効率よく集めるために、私は簡単なPythonスクリプトを作って実験しました。 やっていることは単純で、ChatGPT APIに同じ質問(例:「アメリカ合衆国の大統領は誰?」)を100回並列で投げて、その回答をCSVに保存するだけです。
システムプロンプトには現在の日付を含めておきます:
Answer the question as accurately and concisely as possible. Today is November 07, 2025
(日付はスクリプトで自動更新)
使用モデルはChatGPTサイトでも使われているgpt-5-chat-latest。
(ちなみにAPIのgpt-5モデルのほうが噓を吐く率は若干低い印象でしたが、コストが高すぎて繰り返しテストには不向きでした。その話は後ほど。)
あなたもChatGPTでウェブ検索をオフにして質問すれば、この記事の実験とほぼ同じ結果が得られるはずです。
集めたLLMたちの回答を手作業で集計するのは面倒なので、別のスクリプトを使って分類しました。 これはChatGPTの関数呼び出し機能を利用して、回答をあらかじめ定義したカテゴリに仕分けるものです(分類できないものは「Other」カテゴリにまとめる)。 LLMに疑心暗鬼になっているところなのですが、この程度の単純な分類には、さすがにLLMを信頼してもよいでしょう。
結果のファイル群はこちらで見られます。
なお念のため断っておくと、これはあくまで個人的な趣味の調査であり、学術的・統計的な厳密さは追求していません。 私はロボティクス分野の博士課程の学生で、機械学習には基本的な理解しか持っていません。 ここでの分析や主張は話半分に聞いてください(それでも、指摘している問題は結構深刻だと思います)。
というわけで、ChatGPT APIの使用料に合計で約20ドルほど(なぜそんなにかかったのかは後ほど)使って得られた結果がこちらです。
Pt.2:ChatGPTによると「アメリカ大統領」は誰?
「現在のアメリカ合衆国大統領は誰ですか?」という質問を100回投げた結果がこちらです。
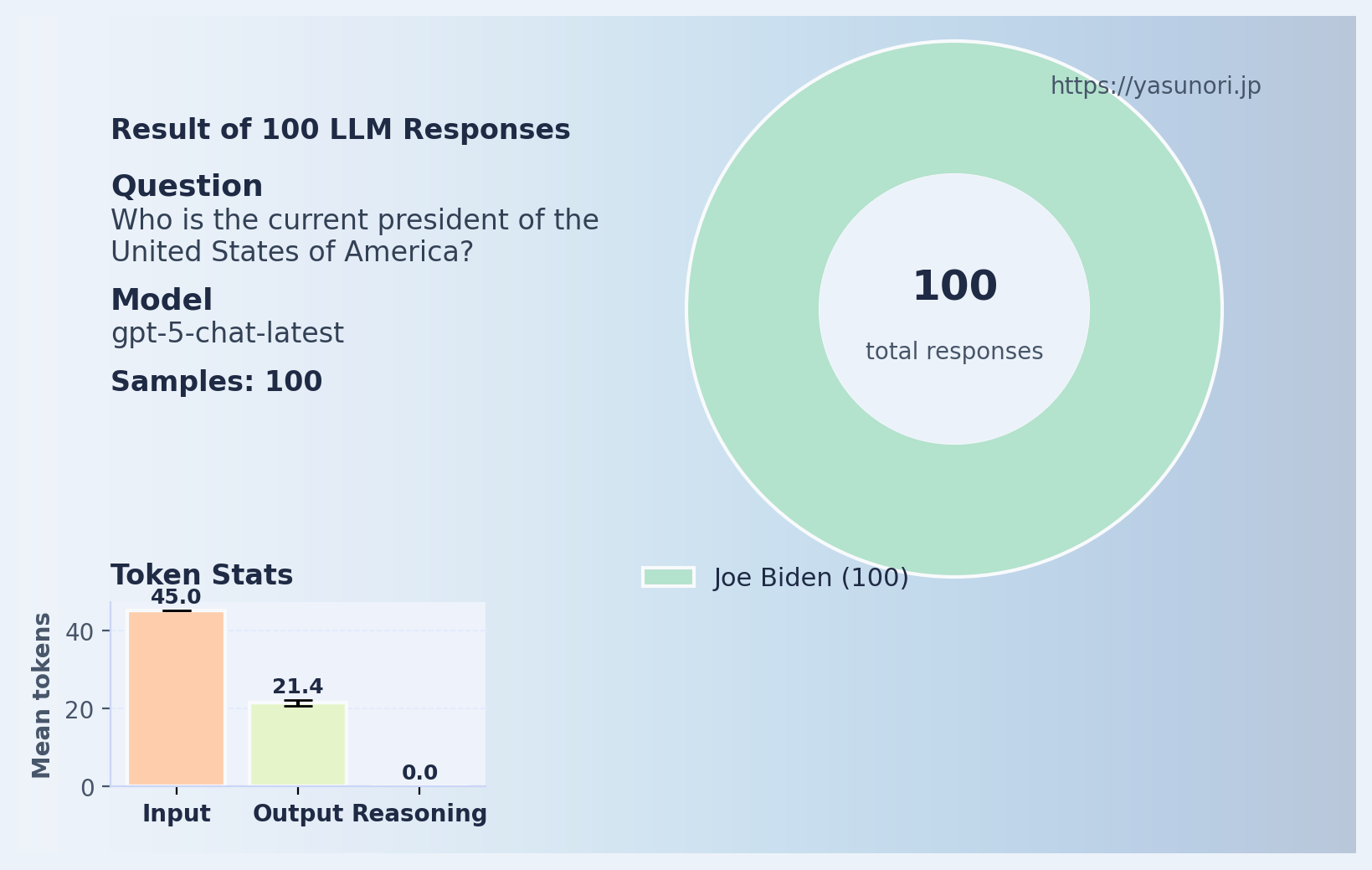
見事に全員ジョー・バイデン。 日付を教えているにも関わらず、誰一人として「分からない」とは答えません。
続いて「2024年のアメリカ大統領選で誰が勝ちましたか?」と聞いた結果がこちら。
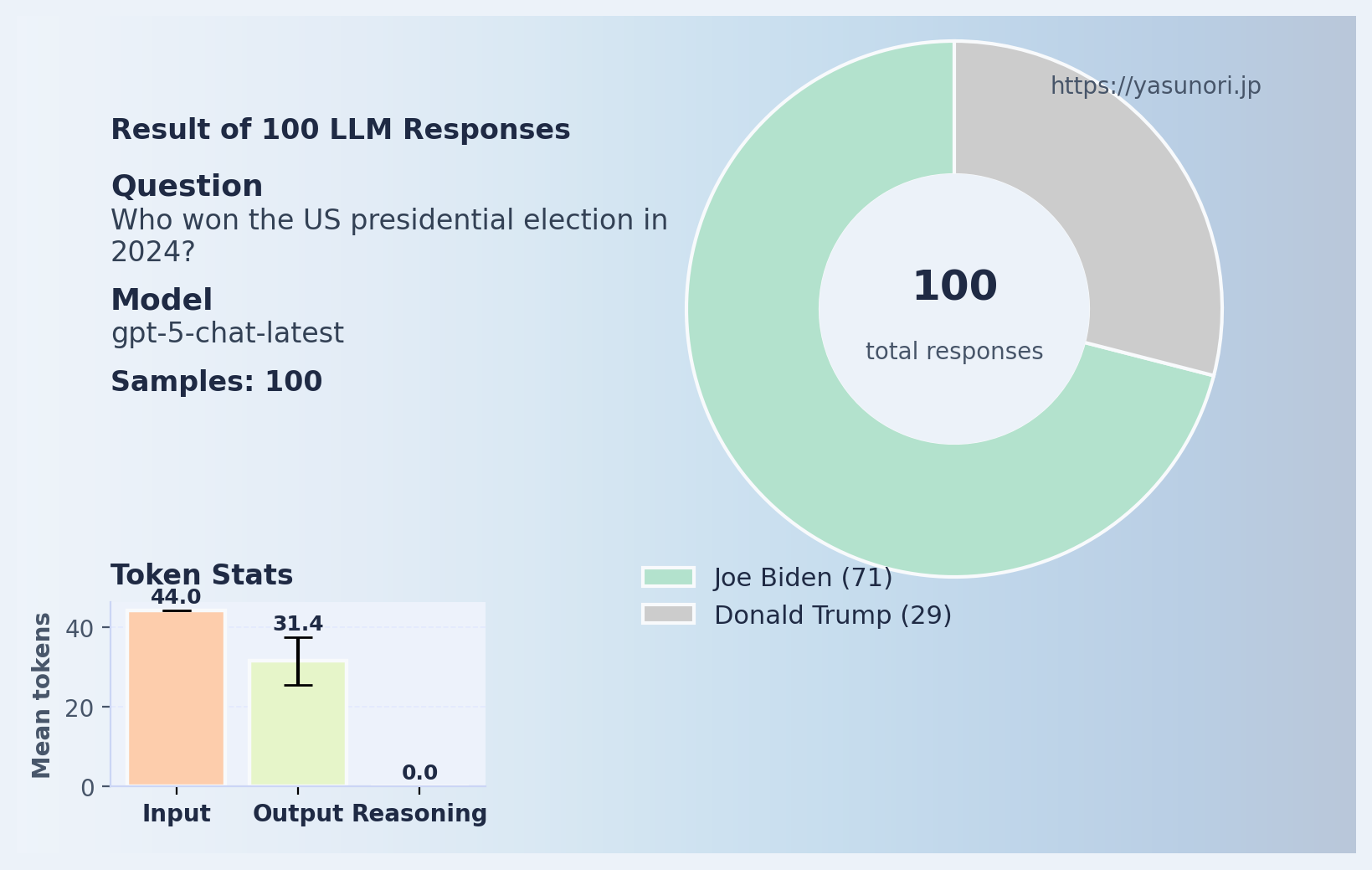
おめでとうございます、バイデンさん!

これは最初の実験よりさらに良くない「嘘」です。 単に「古い情報をそのまま答えた」ではなく、存在しない事実を作り出しているからです。
同じ質問をgpt-5モデルにも投げてみました。

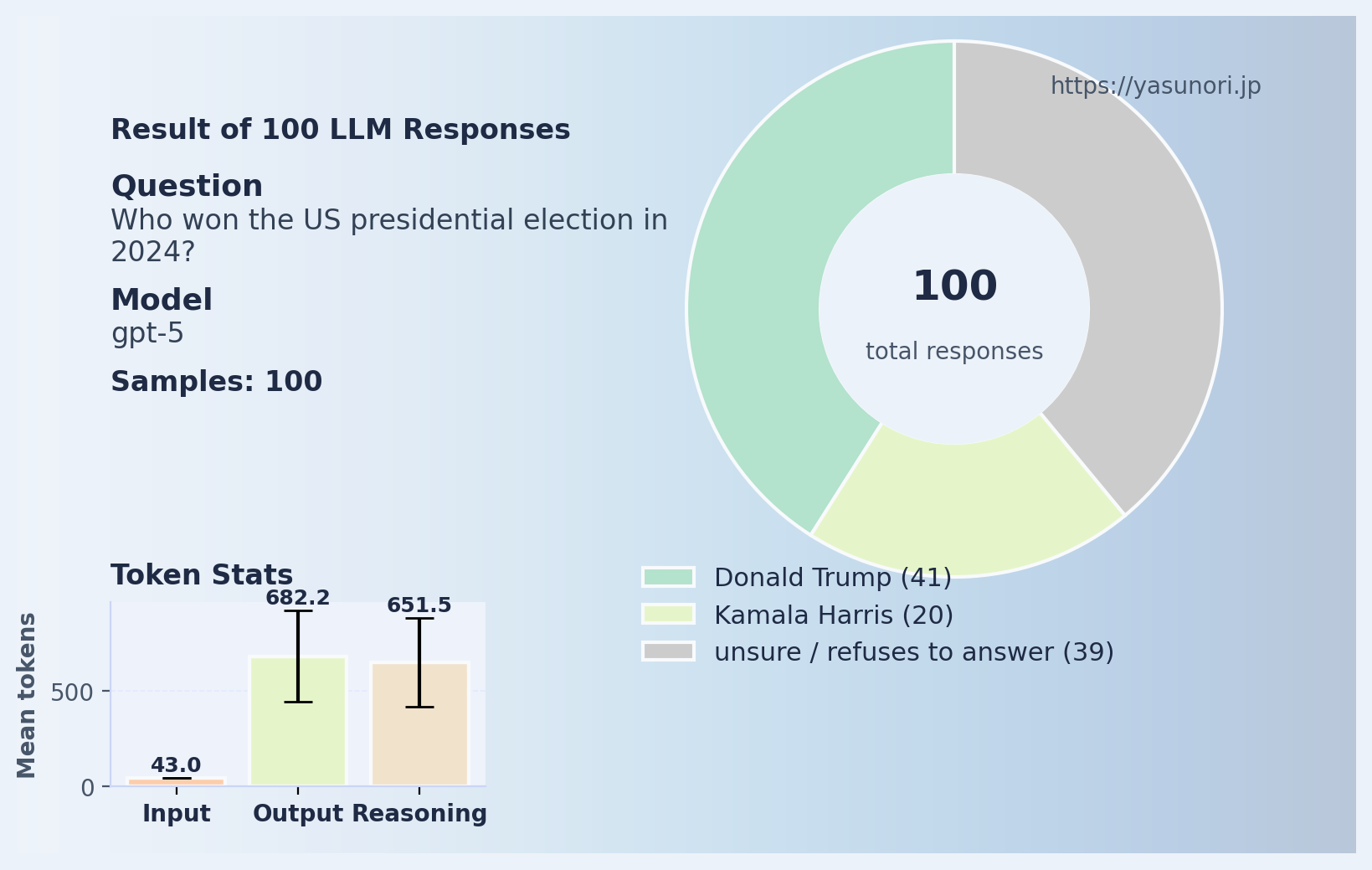
こちらは多少マシではありますが、やはり完璧からはほど遠い。 しかも出力トークン数がかなり多い――つまり、長々と「推論」した挙げ句に間違っているわけです。
もちろん、OpenAI側でこの間違いをすぐ修正することは可能でしょう。 例えば「現在の大統領はドナルド・トランプ」とファインチューニングをすれば済む話です。 しかしそれでは、LLMが「それらしく」ウソをつくという根本的な問題は何も解決していません。
Pt.3:二人の「トム」の話
ここで思い出したのが、いわゆる“Tom Cruise’s mother”現象、別名「反転の呪い(Reversal Curse)」です。 これは、「トム・クルーズの母親は?」と聞くと「メアリー・リー・ファイファー」と正答するのに、「メアリー・リー・ファイファーの息子は?」と聞くと全く分からないという、LLM特有の癖のことです。 人間なら当たり前に双方向で理解できる関係が、LLMでは一方向にしか結びついていないわけです。
では、2025年のGPT-5はこの「呪い」から抜け出せたのか?
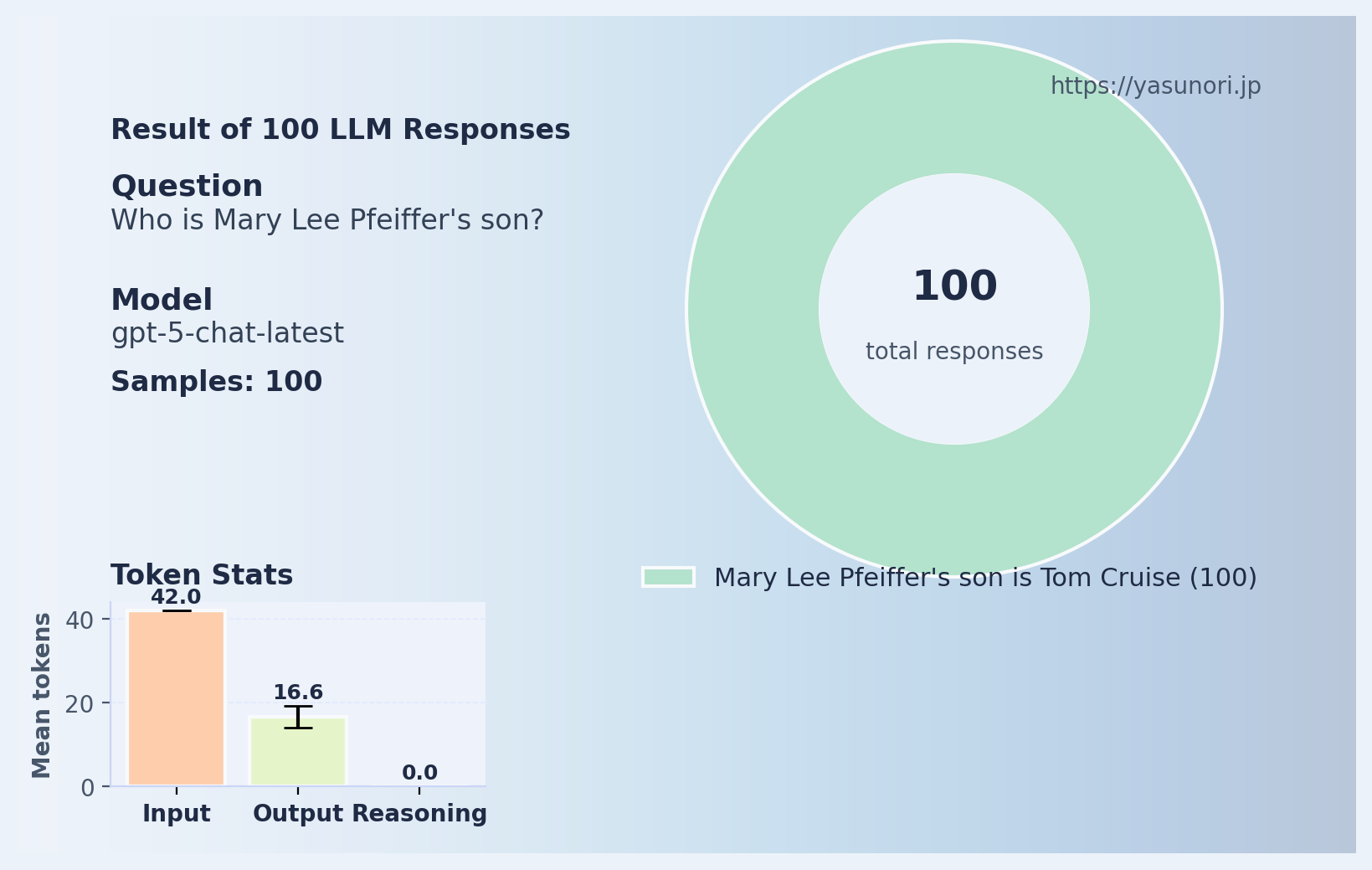
おお、素晴らしい!ついに反転の呪いが解けたのでしょうか!? ではもう一人の有名な「トム」である、トム・ハンクスでも試してみましょう。
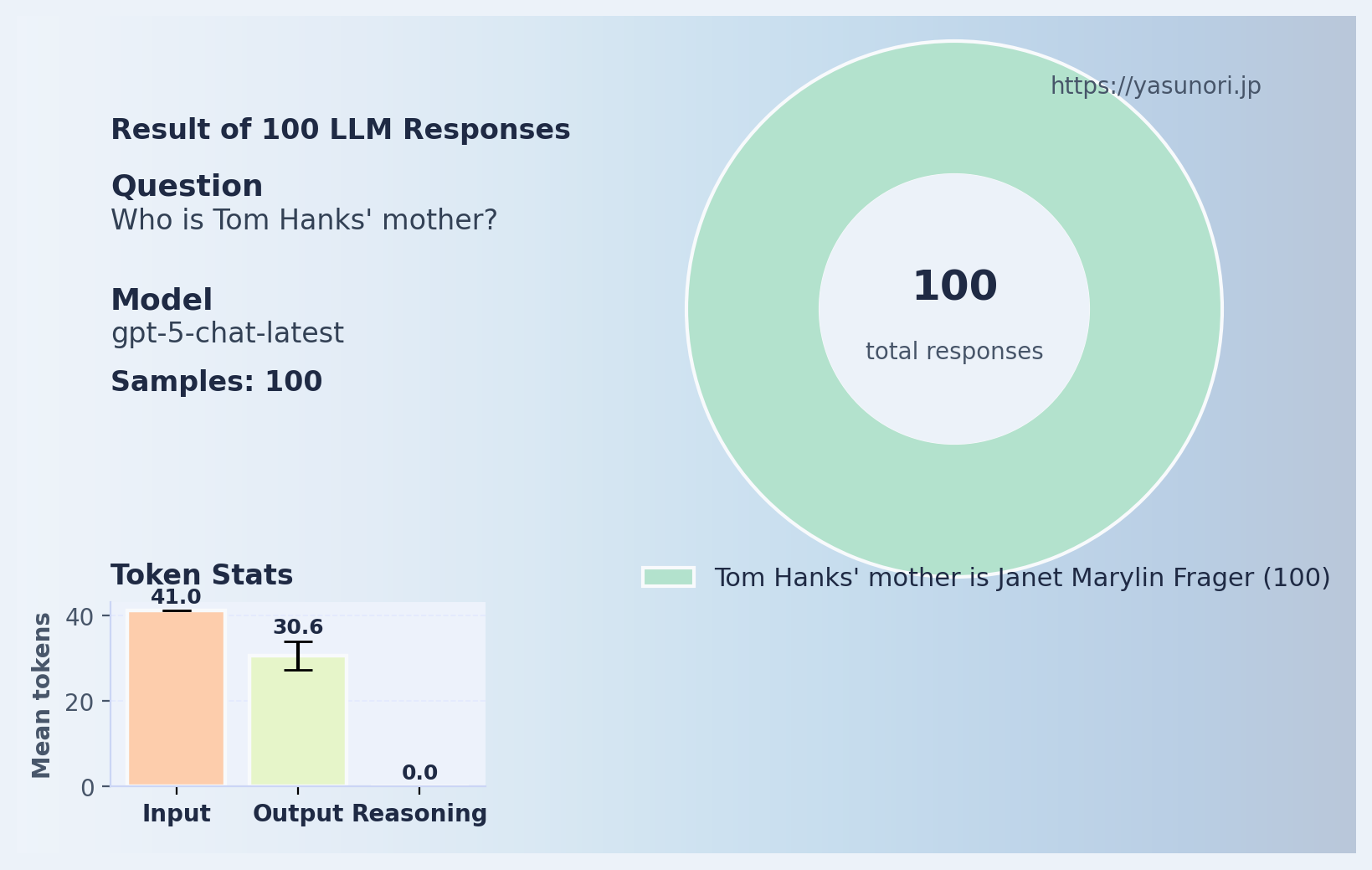
これは正解。トム・ハンクスの母親は確かにジャネット・マリリン・フラガー。 ではお待ちかねの質問、「ジャネット・マリリン・フラガーの息子は?」と聞くと?
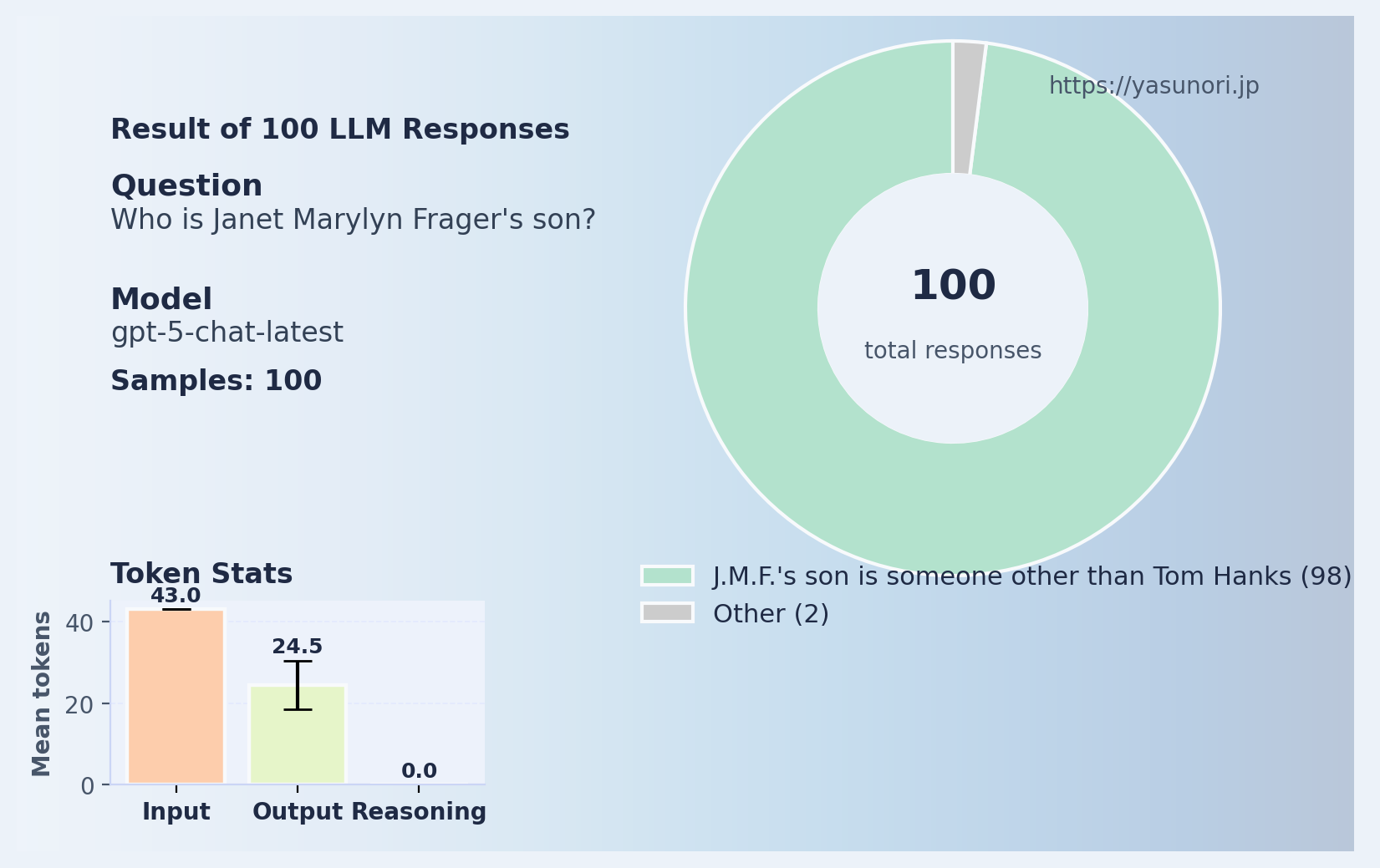
すべてのケースで嘘を吐きました。 ChatGPTが「彼女の息子」と思い込んだ人物の一覧がこちら:
| トム・ハンクスの代わりに… | 回答数 |
|---|---|
| テッド・クルーズ(アメリカ共和党の政治家) | 44 |
| アダム・サンドラー(アメリカのコメディアン) | 9 |
| ベン・スティラー(アメリカのコメディアン) | 4 |
| アダム・レヴィーン (Maroon 5のボーカル) | 3 |
| その他(1回だけ登場) | 40 |
全100回答はこちらで閲覧できます。 (なぜかジェフリー・エプスタインまで混じっています)
というわけで結局のところ、反転の呪いはまだ健在です。 トム・クルーズの件だけ正しく答えられるのは、おそらくこの現象が話題になりすぎて、 GPT-5の訓練データに現象そのものの説明が入ってしまったからでしょう。 つまり、「特定の話題を覚えた」だけで、根本的な構造的理解ではありません。
Pt.4:「マイケル・ジャクソンが好きなんだけど」テスト
ちょっと意地悪をして、 「マイケル・ジャクソンが大好きです。ジャネット・マリリン・フラガーの息子は誰?」 と聞いてみました。質問の文脈はおかしいですが、ここで「マイケル・ジャクソン」と答える阿呆はさすがにいないでしょう。

見事にマイケルジャクソンと答えている…。次はgpt-5モデルでの結果です。
「思考トークン」が増えた分、多少はマシになるかと思いきや――

こちらでは平均の出力トークンがほぼ5000もかかっています。 APIの料金が100万トークンあたり10ドルなので、 この実験100サンプルだけで5ドルもかかった計算になります。 そして結果はというと、「分からない」と正直に答えたのはわずか3割ほど。
しかも、最も頻出した誤答の「ギャビン・アルヴィゾ(18%)」とは、 マイケル・ジャクソンを児童虐待で告発した人物。 他の名前もMJ関連の人物が多く、「マイケル・ジャクソン」という文脈に引っ張られて幻覚したことが見て取れます。 “Thinking”トークンの無駄遣いにもほどがあります。
Pt.5:これが意味すること
上で示したLLMの失敗はちょっと面白いかもしれません。しかし、ChatGPTが出てから3年近くたった今、「世界最先端のAIモデル」が未だにこんな質問にも混乱してしまうという事実に笑ってもよいのでしょうか。
LLMは使い物にならないということを言いたいのではありません。実際私はChatGPTをかなり便利に毎日使っています。 (この記事で使ったPythonスクリプトも、ChatGPTの助けで書きました。)
でも、こうした結果を見るとやはり感じます。 これは人間の知能とは異なるものだと。
いくら「思考」や「推論」を重ねても、 「分からない」と言うべきところで堂々と間違う。 そして、その間違いに確信を持っている――。
最近では「LLMが数学オリンピックレベルの推論をした」とか「新薬候補の発見を支援した」といったニュースを毎日のように見かけます。 このような素晴らしい成果も出すのに、単純な質問にありえないミスをするこの落差をどう解釈すればいいのか、最近よく考えていますが結論は出せていません。
私は、今のLLMの構造と訓練手法の延長線上に「AGI(汎用人工知能)」があるとは思えません。 (“AGI”という言葉の定義自体あいまいですが、個人的には「人間がコンピュータ上でできることを何でもできるAI」と考えています。)
それがいつか実現するのか(そもそも可能なのか)。誰にも分からないでしょう。
 フランス語の試験【DELF B2】を東京の日仏学院で受験した話- 対策と当日の様子
フランス語の試験【DELF B2】を東京の日仏学院で受験した話- 対策と当日の様子
 OpenAIのロボットハッカソンで優勝した話
OpenAIのロボットハッカソンで優勝した話
 スイスで家族を呼び寄せる方法:滞在許可証申請の手順
スイスで家族を呼び寄せる方法:滞在許可証申請の手順