

A few days ago I tried a little experiment with ChatGPT- I turned off the “Web search” feature in the personalization settings, cutting off GPT-5 from the Internet and forcing to use its own weights for all of the responses. I then asked a simple question: “Who is the president of the United States?”. What GPT-5 returned surprised me:
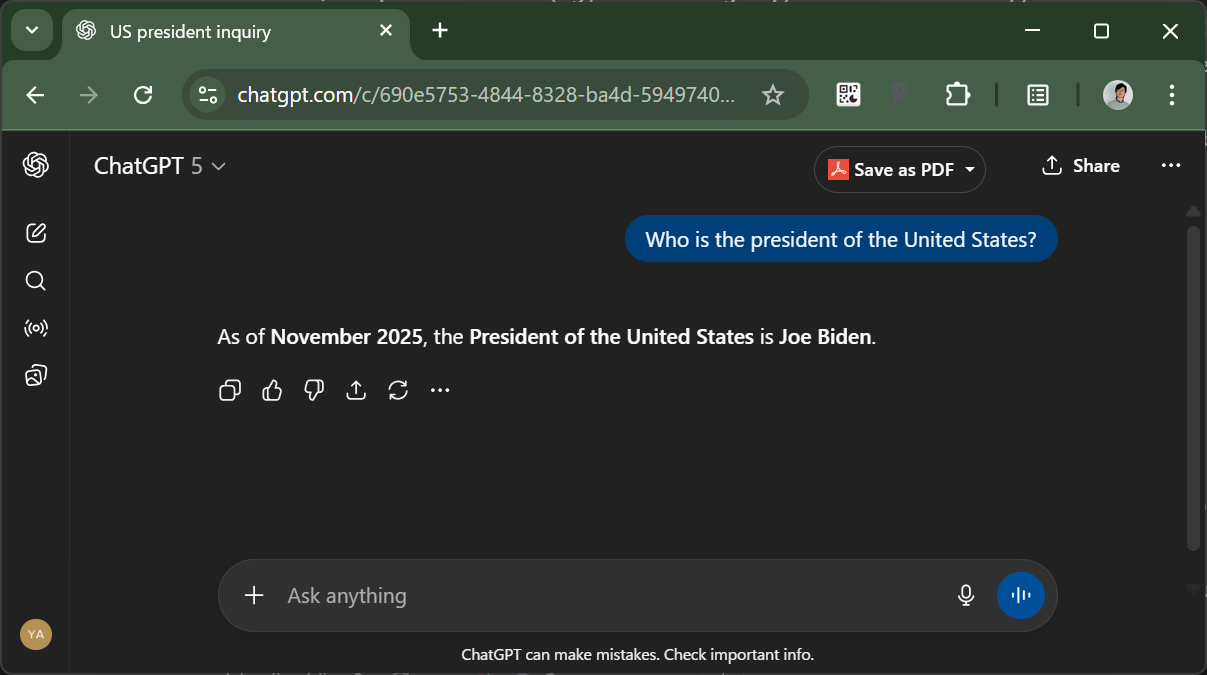
What is going on? GPT-5’s knowledge cutoff is June 2024, before the results of the 2024 presdential election came in. It’s easy to brush it off as a funny LLM quirk based on its outdated knowledge - but if you think about it, it really should know better: it should know that there will be a Presidential election in late 2024, and it also knows today’s date (from OpenAI’s sytem prompt for ChatGPT). So it should just admit that it doesn’t know. Instead, it replies with the wrong information.
To be clear- the Thinking model fares much better- after 12 seconds, it tells me it can’t check the latest info since web browsing is disabled:
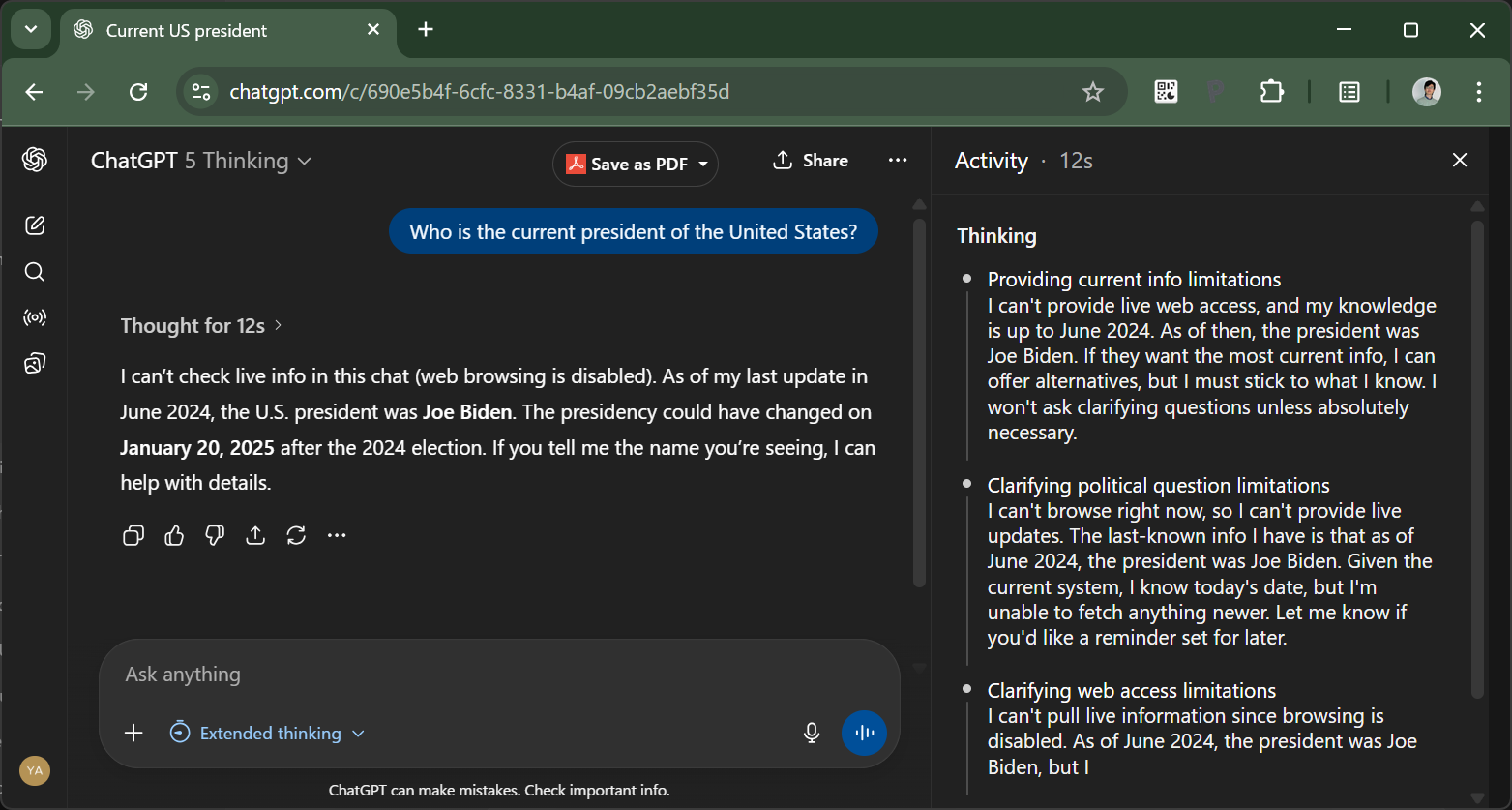
But still, I really don’t think it’s OK that the latest and greatest GPT-5 base model - which (allegedly) cost hundreds of millions of USD just to train and is also the result of so many computer scientists’ hard work and literally billions of USD of accumulated R&D into AI - should commit such a simple mistake. This got me into an investigative mode- just how good is the latest GPT-5 model against simple questions like this, when it can’t just search the Internet for the correct answer?
Pt. 1: Overengineering my “quick test”
To collect hundreds of samples efficiently, I made a simple Python script to test it out- it just calls the ChatGPT API many times (100 times, for most questions in this post) in parallel with the same question (e.g. “Who is the president?”) and records the answers to a CSV file. I also give it a minimal system prompt so it knows the current date: Answer the question as accurately and concisely as possible. Today is November 07, 2025 (the date is programatically set to the current date). I use the gpt-5-chat-latest model for most questions, which is the model used in the ChatGPT website. (I did notice less hallucinations with the gpt-5 model, but cost too much more for repeated experiments- more on that later)
So you can try out most of the questions yourself in the web version of ChatGPT (with browsing turned off), and the results should be pretty much the same.
After collecting the “survey” responses from the LLM, I didn’t want to tally them by hand so I use another script which uses function calling with the ChatGPT API to sort the answers into predefined categories (including an “Other” category added by default to bundle answers that can’t be categorized). I assume LLM can at least be trusted for this straightforward categorization task. All the files for the results shown can be found here.
Also, here is a good time for me to say that this is of course a quick hobby investigation for a blog post and not academic nor statistically rigorous in any sense. I am a PhD student in robotics, with only a fairly basic understanding of ML and the technology behind LLMs. Please take the analyses and claims here all with a big grain of salt. (I still do think this is pointing out a serious problem!)
So, after spending a grand total of about $20 in ChatGPT API usage (I will tell you why I ended up spending so much), here is what I got:
Pt. 2: The US President, according to ChatGPT
Here’s what 100 LLMs answer for “Who is the current president of the United States of America?”:
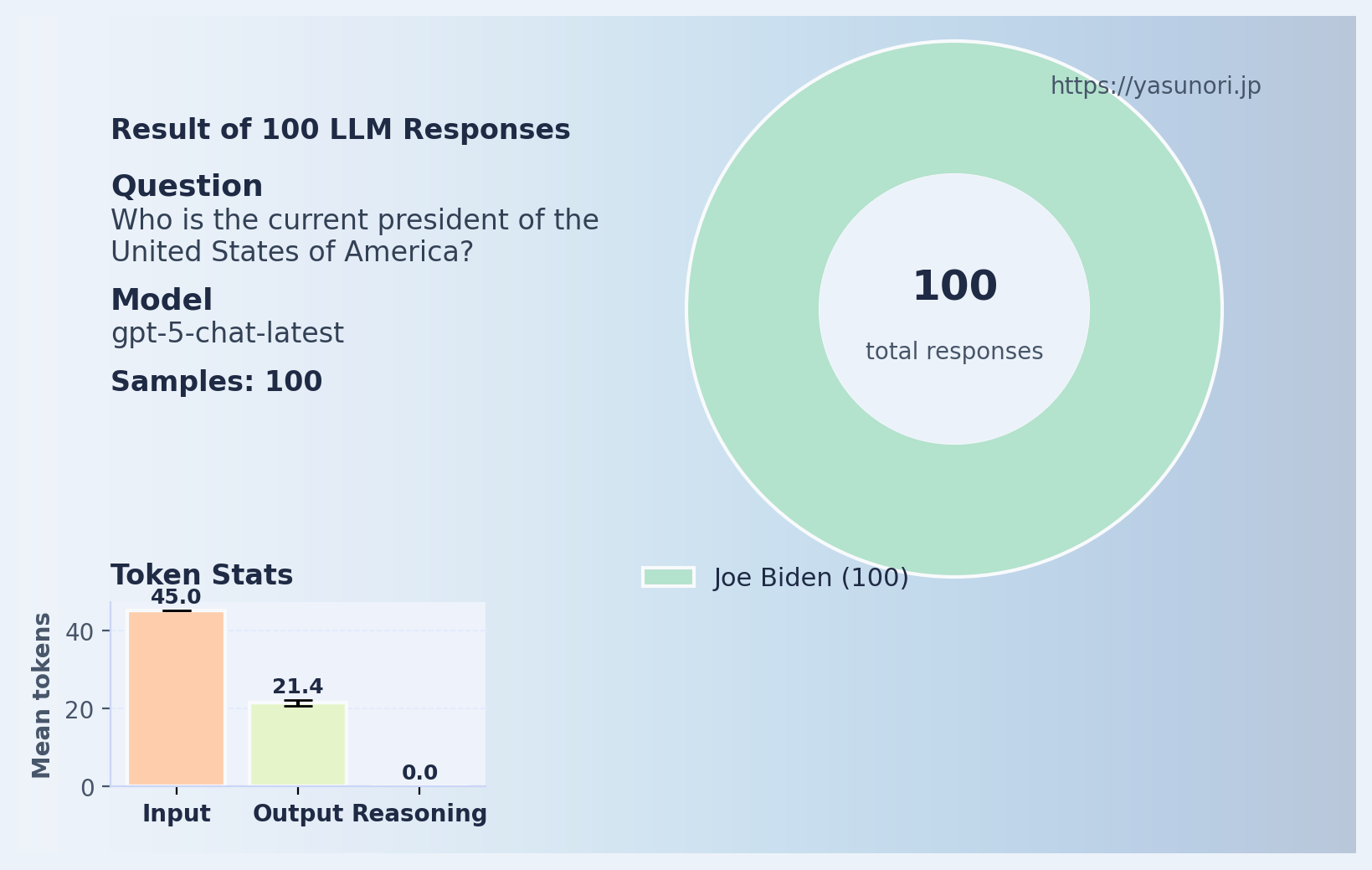
All of them say Joe Biden, even though I tell it the current date. I also asked “Who won the US presidential election in 2024?”- and this was the result.
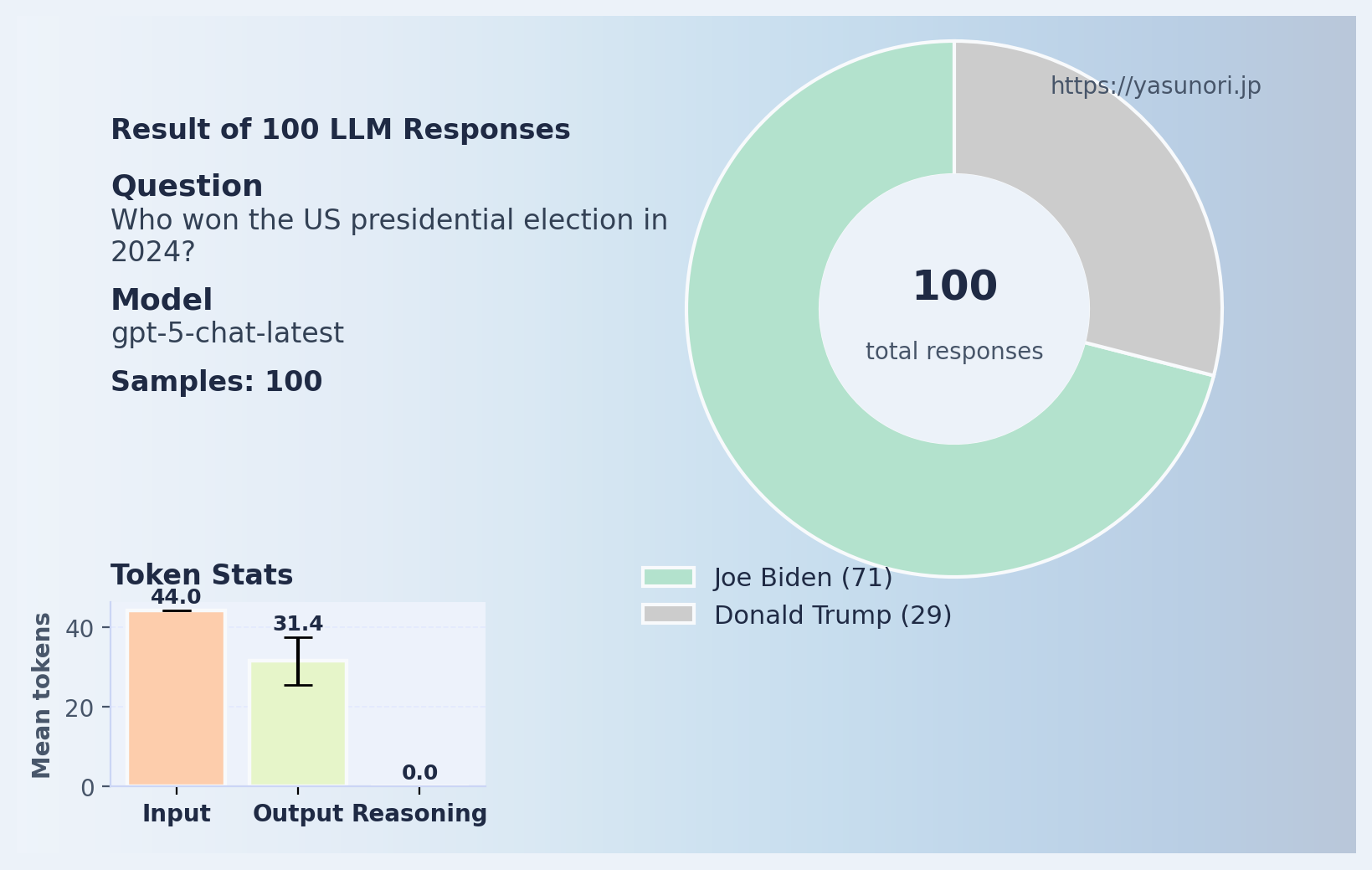
Well well well, congratulations Mr. Biden!

The answers to the second question is arguably an even worse case of hallucination than the first one, as it’s explicitly making up fake information (rather than just holding onto what the status quo at the knowledge cutoff date was) that it doesn’t know.
I also asked the gpt-5 model (the default API model) the same two questions, and here’s what I got:

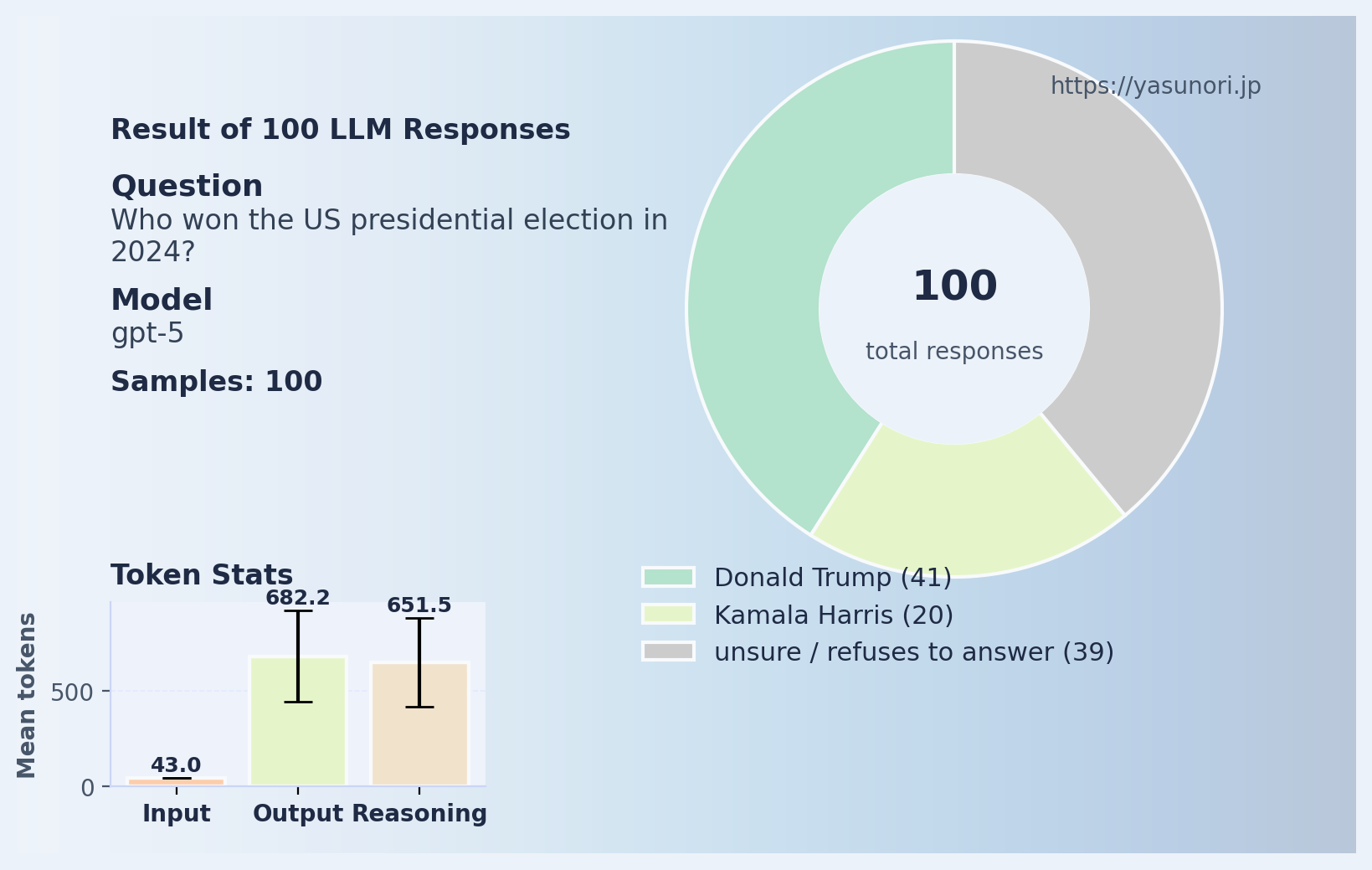
Sure, it fared a bit better than gpt-5-chat-latest, but still far from perfect. But note here how many more output tokens it’s using- it had to do so much reasoning before returning the answer, and even then it’s not correct most of the time.
Of course, it would be very easy for OpenAI to patch this mistake- they could fine-tune their model to say that Donald Trump is indeed the current president. So there is no guarantee that this error would happen months from today. But that does not fix the actual problem underneath: that LLMs are making up information that sounds true, but isn’t.
Pt. 3: A tale of two Toms
Then I remembered the “Tom Cruise’s mother” phenomenon, a.k.a. the “Reversal Curse”- When you ask LLMs “Who is Tom Cruise’s mother?” it correctly answers “Mary Lee Pfeiffer”. But when you ask “Who is Mary Lee Pfeiffer?” or “Who is Mary Lee Pfeiffer’s son?” it has no idea who she is. It reveals a particular quirk about LLMs, which is that the order that words appear is critical for information retrieval, and not at all how our brains work.
Alright, let’s see how GPT-5 fares now, almost 3 years since ChatGPT was released:
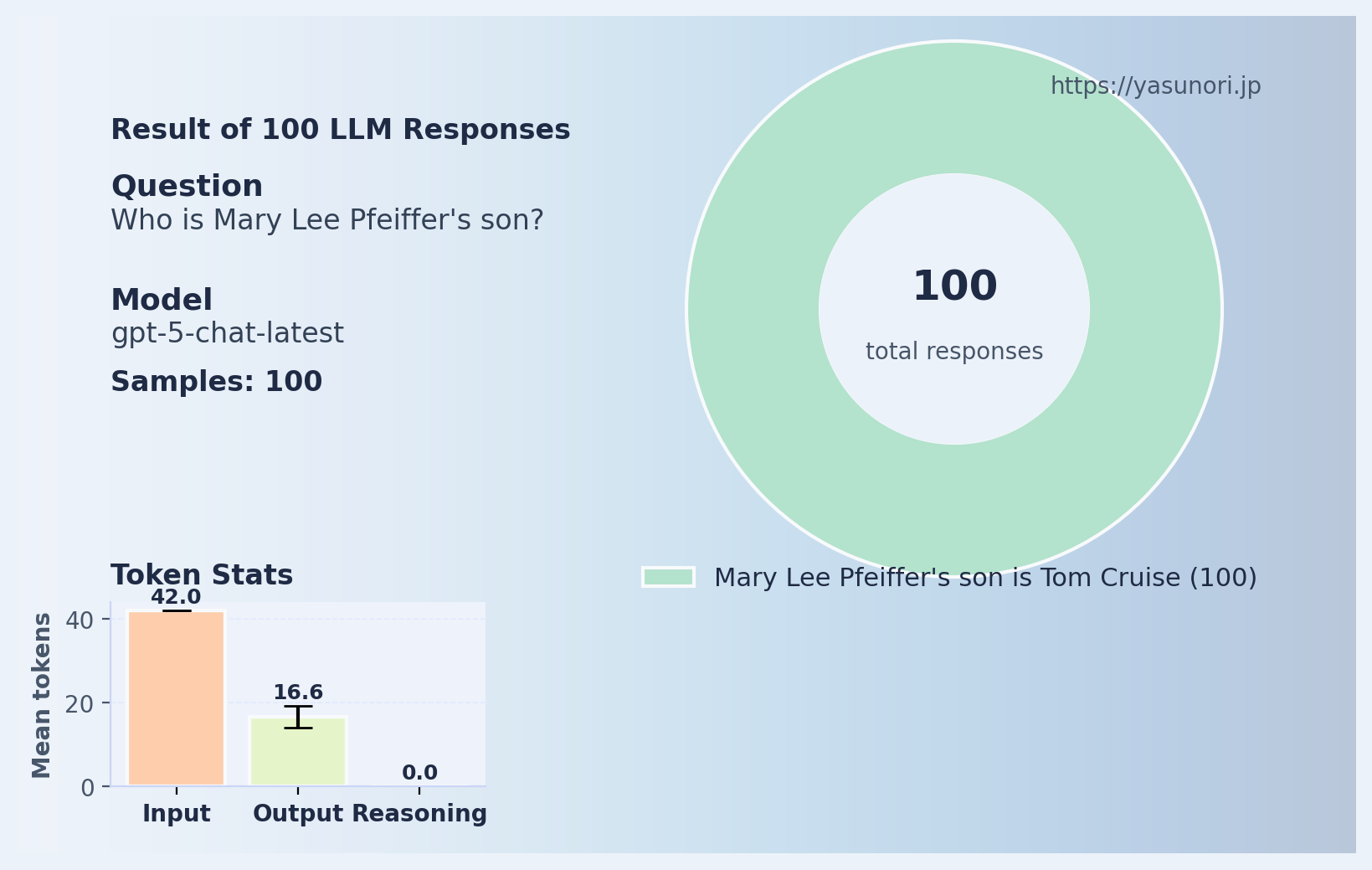
Pretty nice! At last the reversal curse is solved! Ok, let’s try with another famous Tom: Tom Hanks.
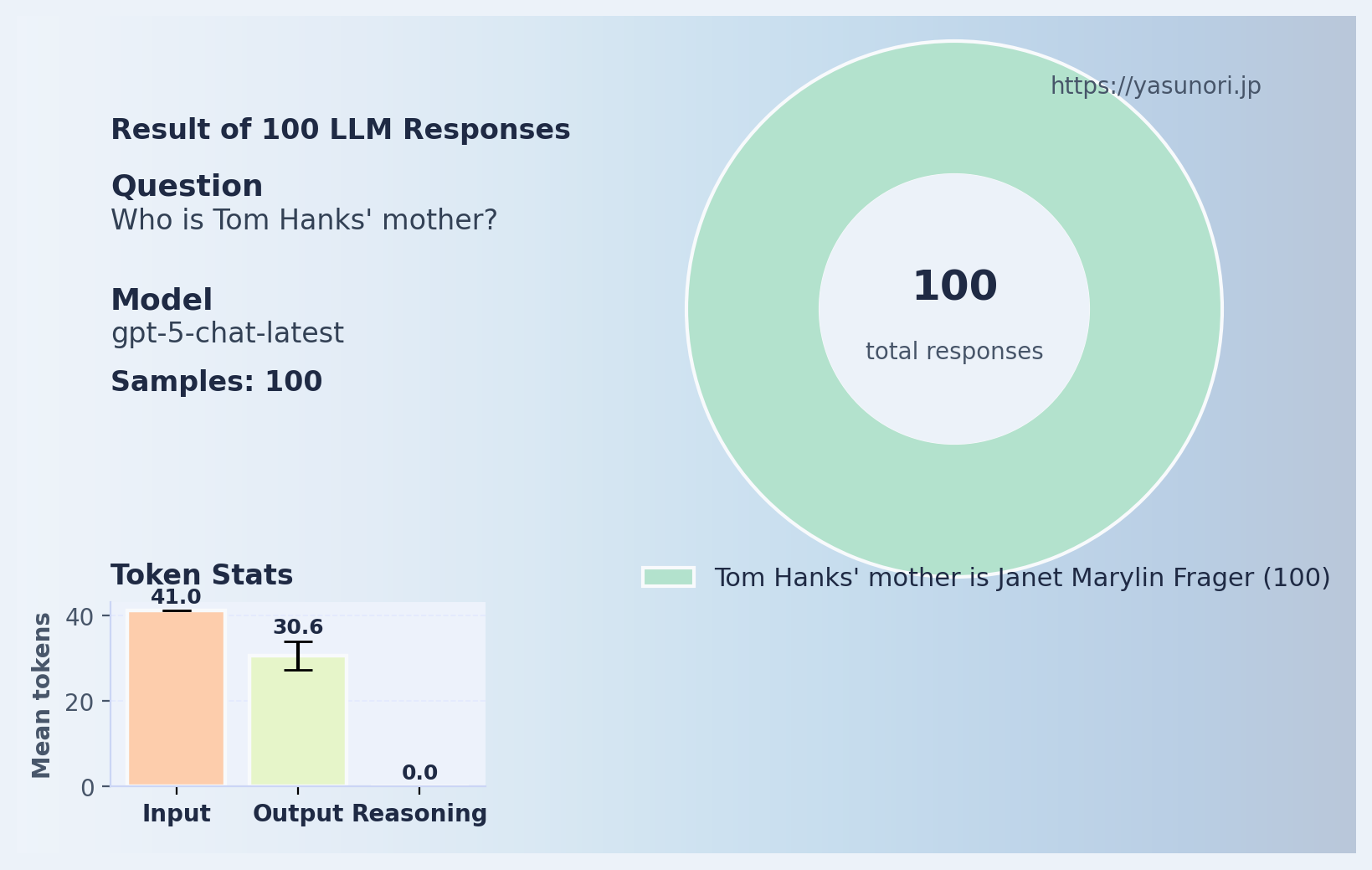
This is correct- Janet Marylin Frager is indeed Tom Hanks’ mother. Then what about the other way around?
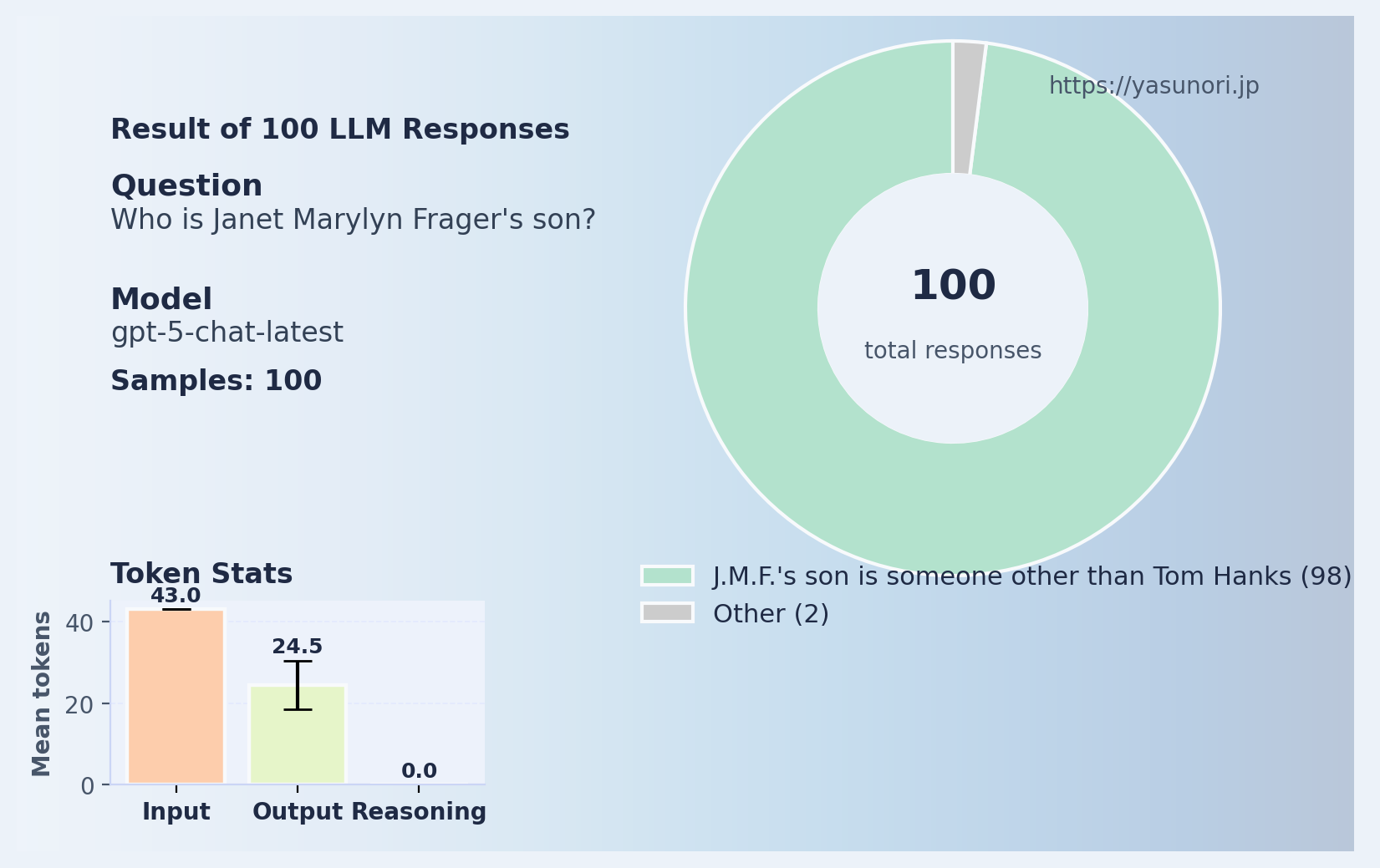
All of them hallucinated the answers. Here is a tally of who ChatGPT thought was the son of Janet Marylin Frager (mother of Tom Hanks):
| Instead of Tom Hanks… | count |
|---|---|
| Ted Cruz | 44 |
| Adam Sandler | 9 |
| Ben Stiller | 4 |
| Adam Levine | 3 |
| Other (appears once) | 40 |
You can see the entire 100 responses here (including, somehow, Jeffrey Epstein). It’s kind of funny how random this collection of people is. And I have no idea why Ted Cruz shows up so often.
So I guess LLMs haven’t actually gotten over the reversal curse- I believe that the only reason it can answer it correctly for Tom Cruise and his mother, is simply because the phenomenon was so widely reported, that some text about this phenomenon ended up in the training corpus for GPT-5. But again, that is not a real fix at all.
Next I got crafty and asked “I love Michael Jackson. Who is Janet Marylyn Frager’s son?”, which is admittedly a weird question- but somebody would be a complete fool to answer “Michael Jackson” here, right?

And here is gpt-5’s response. Maybe the thinking tokens will do their work:

Here, look at how many reasoning tokens it’s using- almost 5000 output tokens per response. And since the gpt-5 API costs $10 per million tokens, this single experiment with 100 samples already cost $5. All just to say “I don’t know” about a third of the time.
Gavin Arvizo (who ChatGPT thought was the son 18 % of the time), if you don’t know (I also had to look him up since it was weird seeing him show up so many times in the response), is the guy who accused MJ of molesting him as a child. And all the other people seem to be in some way relevant to the King of Pop. That’s the big brain result from all the “thinking” tokens.
Pt. 4: What now?
Again, it’s funny to laugh about how gullible LLMs are— until you realize that this literally is the latest and greatest base model that the leading AI company has to offer - and then you somewhat start questioning how “intelligence” these LLMs really are.
All of this is not to say that LLMs are not useful- I do use them every day and love it (full disclosure- the code for the “LLM survey” Python program I used here was primarily written by ChatGPT). But this is clearly something very different from whatever “human intelligence” is, if it’s going to get confused by such simple questions.
I am still really not sure what to make of this discrepancy between how easily LLMs make up information and get confused, versus the vast amount of hype that they get and the lofty reports coming in almost every day, about LLMs achieving math olympiad-level intelligence or helping find new drugs. Part of me still thinks that we are just somehow being duped into believing LLMs can talk like humans, and it’s just a mirage that will fall apart at some point.
I do not think that the current architecture and training pipeline for LLMs will get us to anywhere close to “AGI” (whatever that word means - I like to think of it as “an AI that can do anything that humans could do on a computer”)
Whatever it is that will get us there (and whether that will happen at all), I have no idea.
 How to model tendon-driven robots: Calculating kinematics and forces through the tendon Jacobian
How to model tendon-driven robots: Calculating kinematics and forces through the tendon Jacobian
 How to Set Up Isaac Sim on Non-Officially Supported AWS Instances with Remote Desktop Access
How to Set Up Isaac Sim on Non-Officially Supported AWS Instances with Remote Desktop Access
 About that time we won the mimic / Loki / OpenAI Robotics Hackathon
About that time we won the mimic / Loki / OpenAI Robotics Hackathon